DB Index(인덱스)
업데이트:
Database Index 알아보기
💌 Index(인덱스)란?
Index(인덱스)는 데이터베이스에서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다
인덱스는 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다
관계형 데이터베이스에서는 인덱스는 테이블 부분에 대한 하나의 사본으로 키-필드 값을 가지며 다른 세부 항목은 갖고있지 않는다
고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다
인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다
키-필드 형식으로 저장하기 떄문에 중복된 항목이 등록되는 것을 금지한다(고유성 보장)
- 정리
인덱스는 데이터 레코드(튜플)에 빠르게 접근하기 위해 키-필드 쌍으로(map, dict처럼) 구성된 데이터 구조이다
특정 값을 검색할 때 검색 속도를 높이기 위해(FULL TABLE SCAN하지 않기 위해) 사용한다
📭 Index(인덱스) 단점
- Index 생성시, .mdb 파일 크기가 증가한다
- 한 페이지를 동시에 수정할 수 있는 병행성이 줄어든다
- 인덱스 된 Field에서 Data를 업데이트하거나, Record를 추가 또는 삭제시 성능이 떨어진다
- 데이터 변경 작업이 자주 일어나는 경우, Index를 재작성해야 하므로, 성능에 영향을 미친다
💌 Index(인덱스) 종류
일반적으로 DBMS에서 인덱스 구성 방법에 많이 사용되는 방법은 B-Tree라고 한다
그런데 검색하다보니 B+Tree도 나온다..
B-tree가 일반적인 인덱스 구성 방법이고, B+tree는 B-tree의 확장개념이다
📭 B-Tree
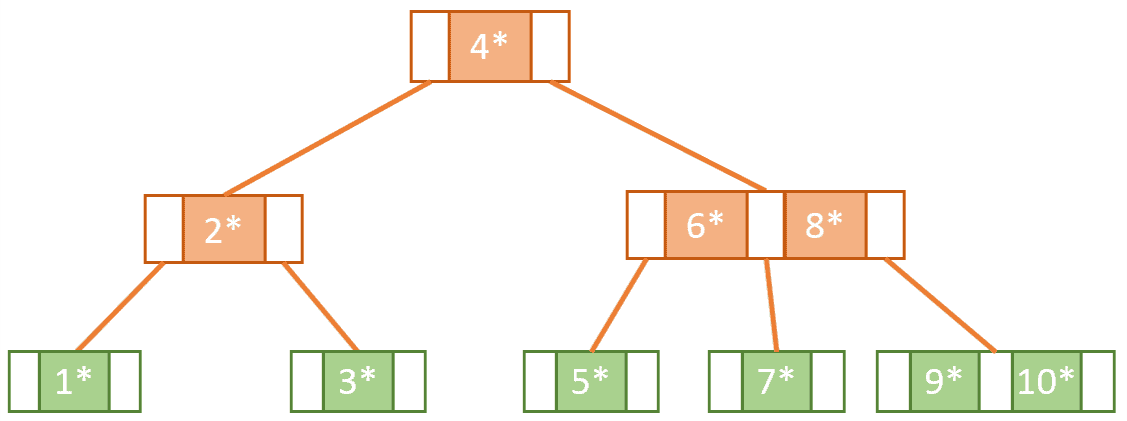
B-Tree는 빠른 쿼리 동작과 검색을 위해 많은 양의 데이터를 저장하도록 설계된 자체 균형 트리 구조(self-balancing tree structure)이다
B-Tree는 노드에 여러 키/값(쌍, Pair, 자료)를 가질 수 있고, 키 순서에 따라 오름차순으로 저장된다
키의 삽입과 삭제 시 노드의 분열과 합병이 발생할 수 있다
- 차수가 m인 B-Tree의 특징(조건)
- 모든 노드는 최대 m개의 서브 노드를 가진다
- 루트(Root)노드와 리프 노드(서브노드가 없는 노드)를 제외한 모든 노드는 최소 m/2개, 최대 m개의 서브 노드를 가진다
- 노드의 자료 수가 k개라면 자식의 수는 k+1개여야 한다
- 모든 리프 노드는 같은 레벨(level)에 나타나야 한다
- 한 노드안에 있는 키 값들은 오름차순을 유지한다
📭 B+Tree
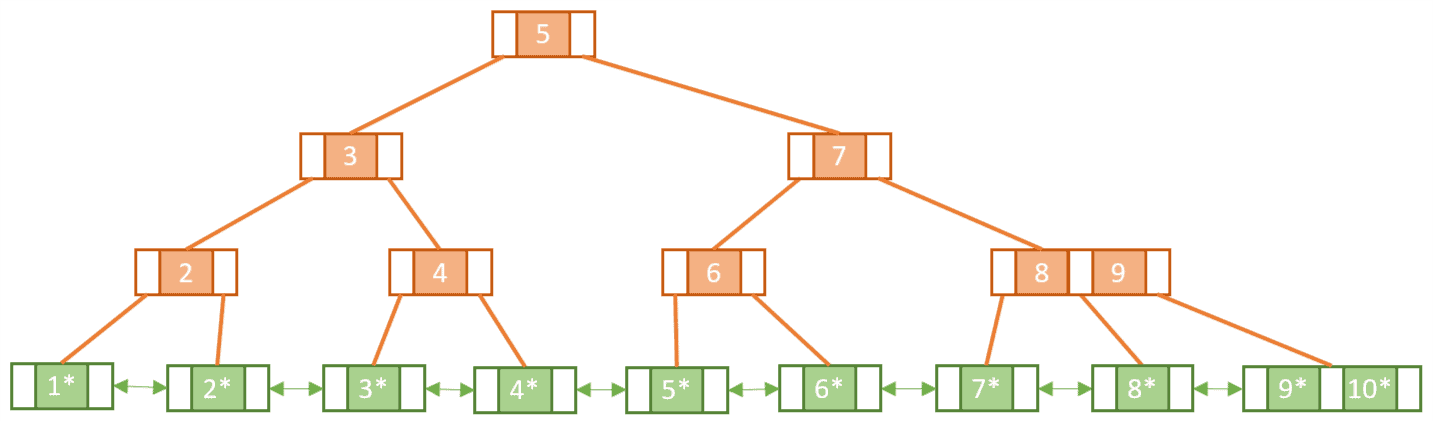
(주황색 노드는 Index node, 초록색 노드는 data node)
B+Tree는 B-Tree의 변형으로 Index node와 Data node(레코드)로 구성되어있다
Index node : 리프 노드에 있는 키 값을 찾아갈 수 있는 라우터 역할(키만 있음)
Data node : 리프 노드끼리 연결리스트로 형성되어있고 data를 가지고 있음
- 차수가 m인 B+Tree의 특징(조건)
- 루트(Root)노드와 리프 노드(서브노드가 없는 노드)를 제외한 모든 노드는 최소 m/2개, 최대 m개의 서브 노드를 가진다
- 루트 노드는 0 또는 2 ~ m개의 서브 노드를 가진다
- 노드의 자료 수가 k개라면 자식의 수는 k+1개여야 한다
- 모든 리프 노드는 같은 레벨(level)에 나타나야 한다
- 한 노드안에 있는 키 값들은 오름차순을 유지한다
- Data node내의 리프 노드들은 모두 링크로 연결되어 있다
📭 비교
| 구분 | B-tree | B+tree |
|---|---|---|
| value 저장 | 노드 모두에 저장 가능 | 오직 리프 노드에만 저장 가능 |
| 트리의 높이 | 높음 | 낮음(한 노드 당 key를 많이 담을 수 있음) |
| 풀 스캔 시 검색 속도 | 모든 노드 탐색 | 리프 노드에서 선형 탐색 |
| 키 중복 | 없음 | 있음(Index node에 중복되어 저장) |
| 검색 | 각 노드마다 데이터가 존재하기 때문에 빠름 | 리프 노드까지 가야 데이터 존재 |
- B-Tree와 비교했을 때 B+Tree의 장점
- 리프 노드를 제외하고 데이터를 담지 않기 때문에 메모리를 확보할 수 있다
- 하나의 노드에 더 많은 key를 담을 수 있어서 트리의 높이는 낮아진다(cache hit를 높일 수 있음)
- 풀 스캔 시, B+Tree는 리프노드에 데이터가 모두 있기 때문에 한번의 선형 탐색하면 되므로 B-Tree에 비해 빠르다
참고
인덱스 (데이터베이스)
[MYSQL]B-tree,B+tree란? (인덱스와 연관지어서)
The Difference Between B-trees and B+trees
Index
댓글남기기